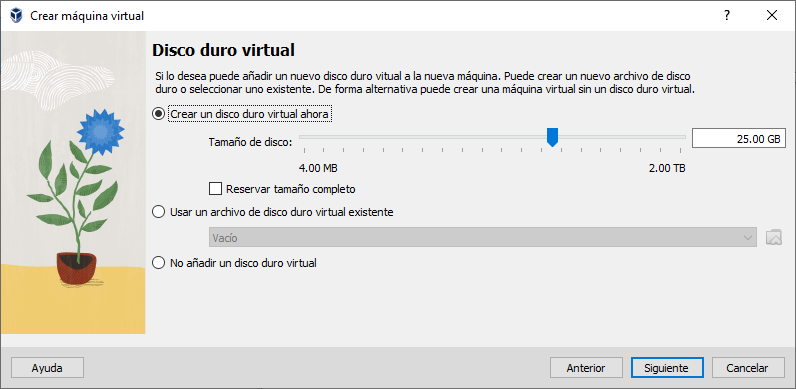
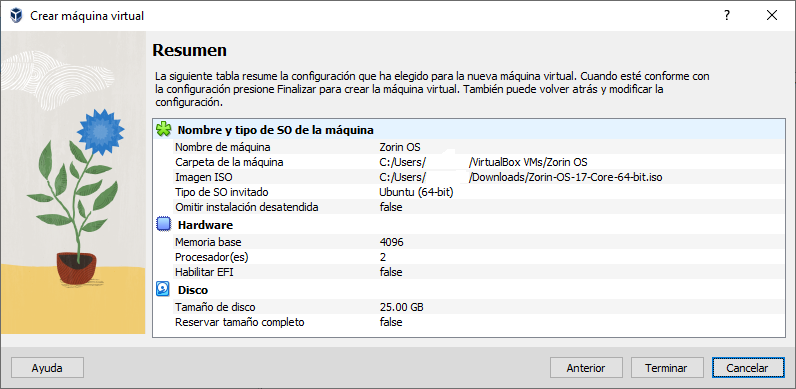
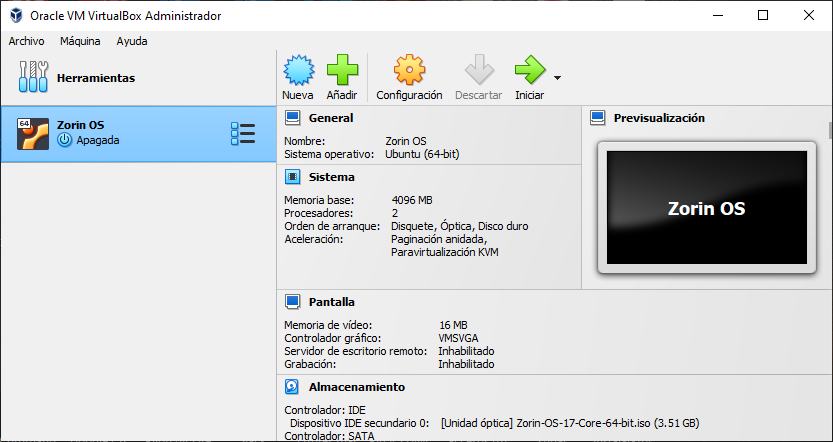
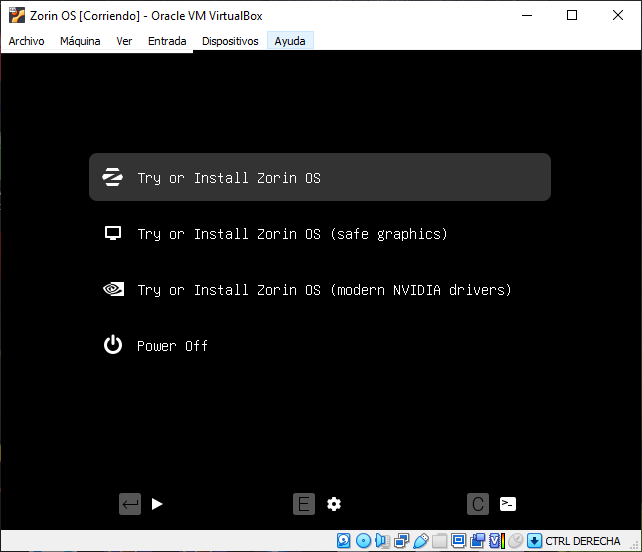
Las copias de seguridad suelen valorarse recién cuando ya es tarde. Un disco que falla, un portátil robado, un ataque de ransomware que cifra todo en segundos (como explicamos en este análisis sobre cómo el ransomware ya no solo cifra archivos, sino que roba tu vida digital). En ese momento, la única diferencia entre una recuperación rápida y una pérdida irreversible es simple: tener un backup funcional.
Hoy el backup ya no es solo copiar archivos a un disco externo. Implica cifrado, versiones históricas, almacenamiento fuera del equipo principal y, cada vez más, una combinación entre nube pública y almacenamiento local. Elegir el software adecuado no es un detalle técnico: es una decisión de continuidad.
Qué hace que un software de backup sea realmente útil
No todos los programas de copias de seguridad ofrecen lo mismo. Algunos destacan por su facilidad de uso, otros por su potencia en entornos profesionales, otros por su flexibilidad o su costo.
Un buen software de backup debería cumplir al menos con esto: permitir copias automáticas, soportar cifrado fuerte, facilitar la restauración y ofrecer destinos externos, ya sea un NAS (por ejemplo, implementado con soluciones como las comparadas en TrueNAS Core vs TrueNAS Scale), un servidor remoto o la nube. De poco sirve un backup que existe, pero que no se puede restaurar cuando se necesita, especialmente si el almacenamiento subyacente no ofrece el rendimiento o la fiabilidad adecuados (algo clave al elegir entre HDD, SSD o NVMe).
Con ese criterio, repasamos algunas de las opciones más conocidas y utilizadas hoy.
Veeam: estándar profesional en protección de datos
Veeam es sinónimo de backup en entornos empresariales. Su enfoque está claramente orientado a infraestructura crítica: servidores físicos, máquinas virtuales y cargas de trabajo en la nube.
Permite realizar copias sin detener sistemas, trabajar con entornos virtualizados como VMware, Hyper-V o Nutanix, y aplicar estrategias avanzadas contra ransomware mediante backups inmutables. Además, se integra de forma nativa con proveedores cloud como AWS, Azure y Google Cloud.
No es un software pensado para uso doméstico. Es una herramienta diseñada para organizaciones que necesitan fiabilidad, escalabilidad y recuperación rápida ante desastres.
Uranium Backup: flexibilidad a un costo accesible
Uranium Backup se ha ganado un lugar por ofrecer muchas funciones avanzadas con un modelo de licencia simple y asequible. Funciona bien tanto en entornos domésticos como en pequeñas y medianas empresas.
Permite respaldar archivos, imágenes de disco, bases de datos, correo, máquinas virtuales y más, algo especialmente importante si tenemos en cuenta que los SSD no son un archivo eterno y pueden degradarse con el tiempo. Puede enviar copias a servidores locales, FTP, NAS o servicios de nube pública como Google Drive, OneDrive, Azure o Amazon S3.
Un punto fuerte es la visibilidad: informes claros que permiten confirmar que el backup se realizó correctamente. Porque un respaldo que no se verifica, en la práctica, no existe.
Duplicati: software libre con enfoque en seguridad
Duplicati es una de las opciones más populares dentro del mundo open source. Es gratuito, multiplataforma y prioriza la seguridad mediante cifrado AES-256 y soporte para GPG.
Está especialmente pensado para backups incrementales de archivos y carpetas, con deduplicación para ahorrar espacio. Se administra desde una interfaz web o por línea de comandos y soporta una enorme variedad de destinos: desde servidores FTP y SSH hasta servicios cloud como Backblaze B2, Amazon S3, Google Drive o OneDrive.
Es una excelente opción para usuarios técnicos que quieren control total sin depender de licencias comerciales.
FBackup: simple y directo para usuarios domésticos
FBackup apunta a la sencillez. Está pensado para usuarios que quieren automatizar copias sin enfrentarse a configuraciones complejas. Permite backups programados, compresión en ZIP, cifrado con contraseña y copias incrementales.
Puede trabajar en local, en red o enviando respaldos a servicios como Google Drive o Dropbox, lo que añade una capa extra de protección frente a ransomware gracias al versionado de archivos en la nube.
No es el más avanzado, pero sí uno de los más fáciles de usar para quien empieza.
Cobian Backup: un clásico que sigue vigente
Cobian Backup es uno de esos programas que muchos han usado alguna vez. Gratuito, ligero y centrado en copias automáticas de archivos y carpetas en sistemas Windows.
Permite compresión, cifrado y respaldo a destinos locales, de red o FTP. Aunque su desarrollo no es tan activo como antes, sigue siendo una opción válida para escenarios simples donde se necesita algo estable y probado.
Eso sí, como con cualquier backup local, la recomendación es siempre combinarlo con un destino externo u offline.
No existe “el mejor” software, existe el más adecuado
Elegir un programa de copias de seguridad no es cuestión de moda ni de marketing. Depende del tipo de datos, del entorno, del presupuesto y del nivel de riesgo aceptable.
En SCI WebHosting insistimos en una idea clave: el valor de un backup no está en crearlo, sino en poder restaurarlo cuando todo falla. El mejor software será siempre aquel que encaje con tu realidad y que puedas mantener funcionando en el tiempo. Si trabajas con WordPress, también puede interesarte por qué es crítico tener copias de seguridad en tu sitio WordPress (antes de que sea tarde).
Porque cuando ocurre el desastre, ya no importa qué tan bonito era el programa. Importa que el backup esté ahí… y funcione.